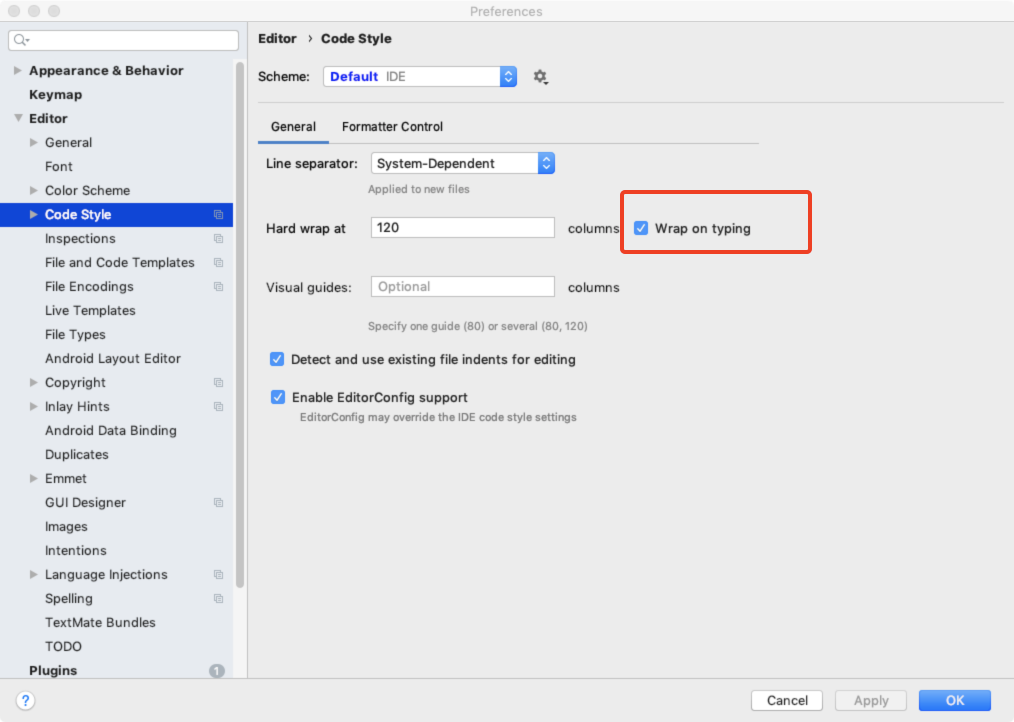
在【File】–>【Settings】–>【Code Sytle】中勾选【Wrap on typing】选项

雄关漫道真如铁 而今迈步从头越
在【File】–>【Settings】–>【Code Sytle】中勾选【Wrap on typing】选项
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>target/lib</outputDirectory>
<excludeTransitive>false</excludeTransitive>
<stripVersion>true</stripVersion>
</configuration>
</execution>
</executions>
</plugin>
<!--java代码打包插件,不会将依赖也打包-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
</plugin>
</plugins>
</build>这是在基于 maven 编写java项目的时候,使用 mvn install 时发生的异常,异常信息如下
[源文件的搜索路径: /Users/Frank/workspace-java/project/app-web/src/main/java,/Users/Frank/workspace-java/project/app-web/target/generated-sources/annotations] [类文件的搜索路径: /Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/rt.jar;/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/jce.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/cldrdata.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/dnsns.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/jaccess.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/jfxrt.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/localedata.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/nashorn.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/sunec.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/ext/zipfs.jar,/System/Library/Java/Extensions/MRJToolkit.jar,/Users/Frank/workspace-java/projects/app-web/target/classes,/Users/Frank/workspace-java/hnProjects/app-configs/target/app-configs-1.0-SNAPSHOT.jar,/Users/Frank/workspace-java/hnProjects/app-utils/target/app-utils-1.0-SNAPSHOT.jar,/Users/Frank/.m2/repository/org/apache/commons/commons-lang3/3.3.2/commons-lang3-3.3.2.jar,/Users/Frank/.m2/repository/commons-httpclient/commons-httpclient/3.1/commons-httpclient-3.1.jar,/Users/Frank/.m2/repository/commons-codec/commons-codec/1.9/commons-codec-1.9.jar,/Users/Frank/.m2/repository/commons-collections/commons-collections/3.2.1/commons-collections-3.2.1.jar,/Users/Frank/.m2/repository/org/apache/httpcomponents/httpclient/4.3.6/httpclient-4.3.6.jar,/Users/Frank/.m2/repository/org/apache/httpcomponents/httpcore/4.3.3/httpcore-4.3.3.jar,/Users/Frank/.m2/repository/commons-logging/commons-logging/1.1.3/commons-logging-1.1.3.jar,/Users/Frank/.m2/repository/commons-beanutils/commons-beanutils/1.9.2/commons-beanutils-1.9.2.jar,/Users/Frank/.m2/repository/org/apache/ant/ant/1.9.4/ant-1.9.4.jar,/Users/Frank/.m2/repository/org/apache/ant/ant-launcher/1.9.4/ant-launcher-1.9.4.jar,/Users/Frank/.m2/repository/net/sf/json-lib/json-lib/2.4/json-lib-2.4-jdk15.jar,/Users/Frank/.m2/repository/commons-lang/commons-lang/2.5/commons-lang-2.5.jar,/Users/Frank/.m2/repository/net/sf/ezmorph/ezmorph/1.0.6/ezmorph-1.0.6.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/junrar-0.7.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/commons-logging-api-1.1.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/commons-vfs2-2.0.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/commons-logging-1.1.1.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/maven-scm-api-1.4.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/plexus-utils-1.5.6.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/maven-scm-provider-svnexe-1.4.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/maven-scm-provider-svn-commons-1.4.jar,/Users/Frank/.m2/repository/com/github/junrar/junrar/0.7/regexp-1.3.jar,/Users/Frank/.m2/repository/commons-logging/commons-logging-api/1.1/commons-logging-api-1.1.jar,/Users/Frank/.m2/repository/org/apache/commons/commons-vfs2/2.0/commons-vfs2-2.0.jar,/Users/Frank/.m2/repository/org/apache/maven/scm/maven-scm-api/1.4/maven-scm-api-1.4.jar,/Users/Frank/.m2/repository/org/codehaus/plexus/plexus-utils/1.5.6/plexus-utils-1.5.6.jar,/Users/Frank/.m2/repository/org/apache/maven/scm/maven-scm-provider-svnexe/1.4/maven-scm-provider-svnexe-1.4.jar,/Users/Frank/.m2/repository/org/apache/maven/scm/maven-scm-provider-svn-commons/1.4/maven-scm-provider-svn-commons-1.4.jar,/Users/Frank/.m2/repository/regexp/regexp/1.3/regexp-1.3.jar,/Users/Frank/.m2/repository/dom4j/dom4j/1.6.1/dom4j-1.6.1.jar,/Users/Frank/.m2/repository/xml-apis/xml-apis/1.0.b2/xml-apis-1.0.b2.jar,/Users/Frank/.m2/repository/org/jsoup/jsoup/1.8.1/jsoup-1.8.1.jar,/Users/Frank/.m2/repository/commons-fileupload/commons-fileupload/1.3.1/commons-fileupload-1.3.1.jar,/Users/Frank/.m2/repository/commons-io/commons-io/2.4/commons-io-2.4.jar,/Users/Frank/.m2/repository/joda-time/joda-time/2.6/joda-time-2.6.jar,/Users/Frank/.m2/repository/com/google/code/gson/gson/2.3.1/gson-2.3.1.jar,/Users/Frank/.m2/repository/com/google/guava/guava/18.0/guava-18.0.jar,/Users/Frank/.m2/repository/com/googlecode/xmemcached/xmemcached/2.0.0/xmemcached-2.0.0.jar,/Users/Frank/.m2/repository/javax/mail/mail/1.4.1/mail-1.4.1.jar,/Users/Frank/.m2/repository/javax/mail/mail/1.4.1/activation.jar,/Users/Frank/.m2/repository/javax/activation/activation/1.1/activation-1.1.jar,/Users/Frank/.m2/repository/com/belerweb/pinyin4j/2.5.0/pinyin4j-2.5.0.jar,/Users/Frank/.m2/repository/org/jdom/jdom/2.0.2/jdom-2.0.2.jar,/Users/Frank/.m2/repository/org/apache/poi/poi-scratchpad/3.10.1/poi-scratchpad-3.10.1.jar,/Users/Frank/.m2/repository/org/apache/poi/poi/3.11/poi-3.11.jar,/Users/Frank/.m2/repository/org/springframework/spring-core/4.1.4.RELEASE/spring-core-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-context/4.1.4.RELEASE/spring-context-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-aop/4.1.4.RELEASE/spring-aop-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/aopalliance/aopalliance/1.0/aopalliance-1.0.jar,/Users/Frank/.m2/repository/org/springframework/spring-beans/4.1.4.RELEASE/spring-beans-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-expression/4.1.4.RELEASE/spring-expression-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-context-support/4.1.4.RELEASE/spring-context-support-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-webmvc/4.1.4.RELEASE/spring-webmvc-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-web/4.1.4.RELEASE/spring-web-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-jdbc/4.1.4.RELEASE/spring-jdbc-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-tx/4.1.4.RELEASE/spring-tx-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/springframework/spring-orm/4.1.4.RELEASE/spring-orm-4.1.4.RELEASE.jar,/Users/Frank/.m2/repository/org/aspectj/aspectjweaver/1.8.4/aspectjweaver-1.8.4.jar,/Users/Frank/.m2/repository/org/hibernate/hibernate-core/4.3.7.Final/hibernate-core-4.3.7.Final.jar,/Users/Frank/.m2/repository/org/jboss/logging/jboss-logging/3.1.3.GA/jboss-logging-3.1.3.GA.jar,/Users/Frank/.m2/repository/org/jboss/logging/jboss-logging-annotations/1.2.0.Beta1/jboss-logging-annotations-1.2.0.Beta1.jar,/Users/Frank/.m2/repository/org/jboss/spec/javax/transaction/jboss-transaction-api_1.2_spec/1.0.0.Final/jboss-transaction-api_1.2_spec-1.0.0.Final.jar,/Users/Frank/.m2/repository/org/hibernate/common/hibernate-commons-annotations/4.0.5.Final/hibernate-commons-annotations-4.0.5.Final.jar,/Users/Frank/.m2/repository/org/hibernate/javax/persistence/hibernate-jpa-2.1-api/1.0.0.Final/hibernate-jpa-2.1-api-1.0.0.Final.jar,/Users/Frank/.m2/repository/org/javassist/javassist/3.18.1-GA/javassist-3.18.1-GA.jar,/Users/Frank/.m2/repository/antlr/antlr/2.7.7/antlr-2.7.7.jar,/Users/Frank/.m2/repository/org/jboss/jandex/1.1.0.Final/jandex-1.1.0.Final.jar,/Users/Frank/.m2/repository/org/hibernate/hibernate-entitymanager/4.3.7.Final/hibernate-entitymanager-4.3.7.Final.jar,/Users/Frank/.m2/repository/org/hibernate/hibernate-ehcache/4.3.7.Final/hibernate-ehcache-4.3.7.Final.jar,/Users/Frank/.m2/repository/org/hibernate/hibernate-validator/5.1.3.Final/hibernate-validator-5.1.3.Final.jar,/Users/Frank/.m2/repository/javax/validation/validation-api/1.1.0.Final/validation-api-1.1.0.Final.jar,/Users/Frank/.m2/repository/com/fasterxml/classmate/1.0.0/classmate-1.0.0.jar,/Users/Frank/.m2/repository/org/freemarker/freemarker/2.3.21/freemarker-2.3.21.jar,/Users/Frank/.m2/repository/net/sf/ehcache/ehcache-core/2.6.10/ehcache-core-2.6.10.jar,/Users/Frank/.m2/repository/com/alibaba/fastjson/1.2.4/fastjson-1.2.4.jar,/Users/Frank/.m2/repository/com/alibaba/druid/1.0.12/druid-1.0.12.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/../lib/jconsole.jar,/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/../lib/tools.jar,/Users/Frank/.m2/repository/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar,/Users/Frank/.m2/repository/com/microsoft/sqlserver/sqljdbc4/4.0/sqljdbc4-4.0.jar,/Users/Frank/.m2/repository/org/slf4j/slf4j-api/1.7.9/slf4j-api-1.7.9.jar,/Users/Frank/workspace-java/hnProjects/app-dao/target/app-dao-1.0-SNAPSHOT.jar,/Users/Frank/workspace-java/hnProjects/app-service/target/app-service-1.0-SNAPSHOT.jar,/Users/Frank/.m2/repository/javax/servlet/jsp/jstl/javax.servlet.jsp.jstl-api/1.2.1/javax.servlet.jsp.jstl-api-1.2.1.jar,/Users/Frank/.m2/repository/javax/el/javax.el-api/2.2.4/javax.el-api-2.2.4.jar,/Users/Frank/.m2/repository/javax/servlet/javax.servlet-api/3.1.0/javax.servlet-api-3.1.0.jar,/Users/Frank/.m2/repository/javax/servlet/jsp/javax.servlet.jsp-api/2.3.1/javax.servlet.jsp-api-2.3.1.jar,.] 致命错误: 在类路径或引导类路径中找不到程序包 java.lang [INFO] ------------------------------------------------------------- [ERROR] COMPILATION ERROR : [INFO] ------------------------------------------------------------- [ERROR] An unknown compilation problem occurred [INFO] 1 error [INFO] ------------------------------------------------------------- [INFO] ------------------------------------------------------------------------ [INFO] Reactor Summary: [INFO] [INFO] Projects :: APP :: Parent ........................... SUCCESS [ 0.357 s] [INFO] Projects :: APP :: Utils ............................ SUCCESS [ 1.257 s] [INFO] Projects :: APP :: Configs .......................... SUCCESS [ 0.374 s] [INFO] Projects :: APP :: Dao .............................. SUCCESS [ 0.172 s] [INFO] Projects :: APP :: Service .......................... SUCCESS [ 0.152 s] [INFO] Projects :: APP :: Admin ............................ SUCCESS [ 1.273 s] [INFO] Projects :: APP :: Web .............................. FAILURE [ 0.081 s] [INFO] xxx ................................................. SKIPPED [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total time: 5.426 s [INFO] Finished at: 2016-07-22T21:26:15+08:00 [INFO] Final Memory: 39M/310M [INFO] ------------------------------------------------------------------------ [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.2:compile (default-compile) on project app-web: Compilation failure [ERROR] An unknown compilation problem occurred [ERROR] -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command [ERROR] mvn -rf :app-web 原因在于 compiler 插件的配置。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId> <version>${maven.compiler.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target> <encoding>${project.build.sourceEncoding}</encoding> <showWarnings>true</showWarnings>
<compilerArguments>
<verbose />
<!-- 这个配置很特殊:windows下使用分号(;)分隔,linux/mac下使用冒号(:)分隔 --> <bootclasspath>${java.home}/lib/rt.jar;${java.home}/lib/jce.jar</bootclasspath> </compilerArguments>
</configuration>
</plugin> <!-- ... --> 配置中14行的分隔符问题,在windows下使配置中分隔符问题,在windows下使用maven 应该使用分号(;)分隔,linux/mac 下使用(:)分隔。
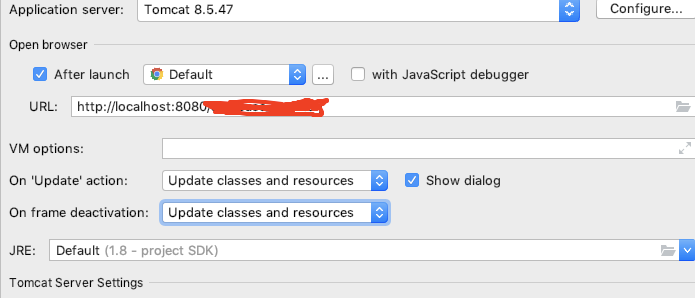
在tomcat中配置热更新属性。配置一下就行了
@RequestParam (org.springframework.web.bind.annotation.RequestParam)用于将指定的请求参数赋值给方法中的形参。
有三个属性:
(1)value:请求参数名(必须配置)
(2)required:是否必需,默认为 true,即 请求中必须包含该参数,如果没有包含,将会抛出异常(可选配置)
(3)defaultValue:默认值,如果设置了该值,required 将自动设为 false,无论你是否配置了required,配置了什么值,都是 false(可选配置)
1为演示效果,首先需要创建一个测试控制类,然后创建一个测试方法,如图所示,方法里添加一个参数,此时方法参数没有添加注解
@RequestParam String inputStr
// 下面的对传入参数指定为aa,如果前端不传aa参数名,会报错
@RequestParam(value="aa") String inputStr 用StandardCharsets.UTF_8 返回”UTF-8″这个字符
public final class StandardCharsets {
private StandardCharsets() {
throw new AssertionError("No java.nio.charset.StandardCharsets instances for you!");
}
/**
* Seven-bit ASCII, a.k.a. ISO646-US, a.k.a. the Basic Latin block of the
* Unicode character set
*/
public static final Charset US_ASCII = Charset.forName("US-ASCII");
/**
* ISO Latin Alphabet No. 1, a.k.a. ISO-LATIN-1
*/
public static final Charset ISO_8859_1 = Charset.forName("ISO-8859-1");
/**
* Eight-bit UCS Transformation Format
*/
public static final Charset UTF_8 = Charset.forName("UTF-8");
/**
* Sixteen-bit UCS Transformation Format, big-endian byte order
*/
public static final Charset UTF_16BE = Charset.forName("UTF-16BE");
/**
* Sixteen-bit UCS Transformation Format, little-endian byte order
*/
public static final Charset UTF_16LE = Charset.forName("UTF-16LE");
/**
* Sixteen-bit UCS Transformation Format, byte order identified by an
* optional byte-order mark
*/
public static final Charset UTF_16 = Charset.forName("UTF-16");
}直接用
@Test
public void testUTF8() {
System.out.println(StandardCharsets.UTF_8.name()); //UTF-8
}isEmpty()
public static boolean isEmpty(String str) {
return str == null || str.length() == 0;
}
isBlank()
public static boolean isBlank(String str) {
int strLen;
if (str != null && (strLen = str.length()) != 0) {
for(int i = 0; i < strLen; ++i) {
// 判断字符是否为空格、制表符、tab
if (!Character.isWhitespace(str.charAt(i))) {
return false;
}
}
return true;
} else {
return true;
}
}
结论
通过以上代码对比我们可以看出:
1.isEmpty 没有忽略空格参数,是以是否为空和是否存在为判断依据。
2.isBlank 是在 isEmpty 的基础上进行了为空(字符串都为空格、制表符、tab 的情况)的判断。(一般更为常用)
大家可以看下面的例子去体会一下。
StringUtils.isEmpty(“yyy”) = false
StringUtils.isEmpty(“”) = true
StringUtils.isEmpty(” “) = false
StringUtils.isBlank(“yyy”) = false
StringUtils.isBlank(“”) = true
StringUtils.isBlank(” “) = true
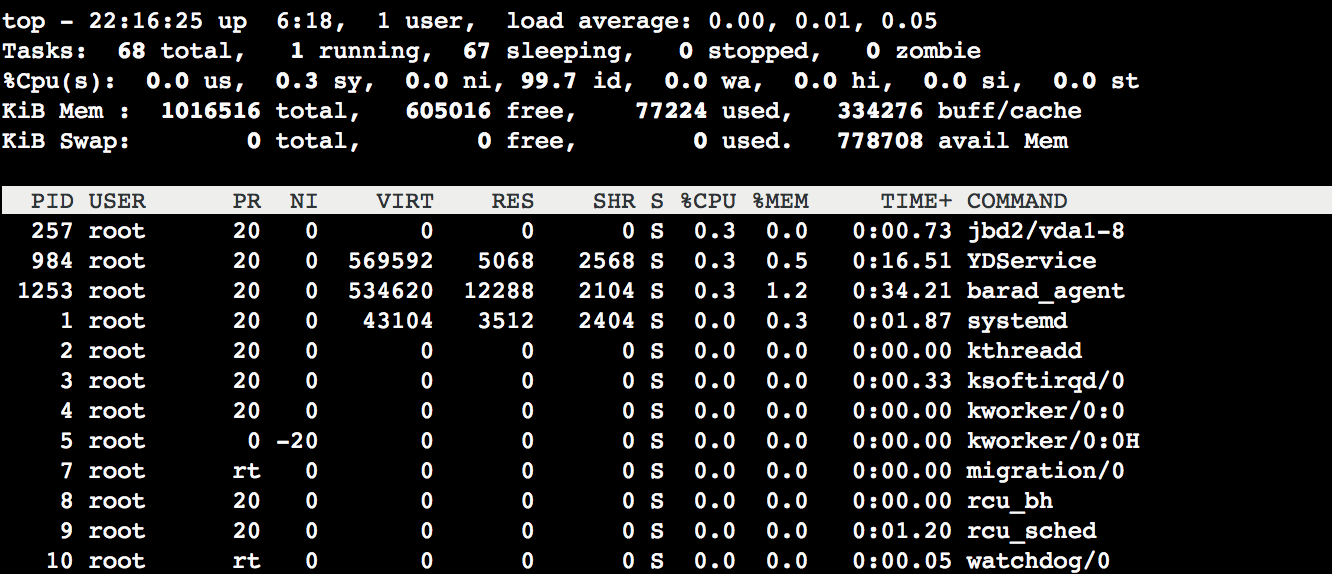
Top:Linux 系统下常用的监控工具,用于实时获取进程级别的 CPU 或内存使用情况。以下图 top 命令的输出信息为例。
Top 命令的输出信息主要分为两部分,上半部分显示 CPU 和内存资源的总体使用情况:
下半部分以进程为维度显示资源的占用情况:
ES 建议分配不超过 50% 的内存给 JVM,同时总量不要大于 32 GB。
# 设置 max heap size
export ES_HEAP_SIZE=10g
# 查看当前 max heap size
GET /_cat/nodes?h=heap.max
JVM 使用的内存越小,留给 Lucene 的内存就越多,就可以有更多的内存作为缓存,提高性能。但是 JVM 的内存也不能太小,否则会导致 OOM 或 FullGC,而这会导致节点超时被移出,shards reallocate 又会极大的影响性能。
ES 有两个组件需要使用内存:
JVM 主要存放各种 in-memory 的数据结构,Lucene 负责底层的存储。因为 Lucene 依赖操作系统的缓存机制,而操作系统会把所有的空闲内存分配为 page cache,所以如果 JVM heap 过大,会导致 segment 没有足够的 cache。
64 位的指针会带来额外的性能开销,为了提高性能,Java 会采用 compressed oops 的技术,依然使用 32 位的指针,不过指针用来表示 object offsets,此时一个 32 位指针可以表示 4 G 的 object,而不是 4 G 的 bytes,这种情况下,可以让 heap 的空间达到 32 GB。但如果给 heap 分配的空间超过 32 GB,Java 就会采用 64 bit 的 ordinary object pointers(OOP),运行性能会出现显著下降,据估测,heap 大小达到 40-50 GB 时,性能才与 32 GB 时相同。
如果机器内存远大于 32 GB,也建议不要给 heap 设置超过 32 GB 的内存,可以考虑把机器划分为多个 64 GB 内存的节点,然后每个节点分配 32 GB heap。
JVM 会申请一大块内存,称为 heap。heap 中的所有对象会被分为两个集合:Young(Eden)和 Old,一般来说 Old 的空间会显著的大于 Young。
每当 Young 的空间耗尽时,就会启动 young gc,所有幸存的对象会被标记为 survivor,如果一个对象连续两次被标记为 survivor,就会被放入 Old。Old 类似,空间耗尽时会触发 old gc。这两种 GC 都会导致 stop-the-world。不过因为 young 空间较小,gc 耗时一般也很短。带来严重暂停的一般都是 old gc。
ES 默认当 JVM heap 超过 75% 的时候启动 GC,所以应该监控 heap 使用率超过 80% 的情形,此时 gc 已无法有效的清理内存。默认的 heap 是 1GB,这个值太小,实际上线时要根据内存大小进行调整(一般小于 50% 内存)。但是 JVM heap 太大时,会导致 GC 时间过长。如果超过 30s 无响应,就会被 master 移出集群。
相关指标:
jvm.gc.collectors.young.collection_countjvm.gc.collectors.young.collection_time_in_millisjvm.gc.collectors.old.collection_countjvm.gc.collectors.old.collection_time_in_millisjvm.mem.heap_used_percentjvm.mem.heap_committed_in_bytesES 默认使用 CMS,在 Heap 较大时性能会比较差(更长的 Stop-the-world),相较之下 G1 在大 heap 时性能更好,但是 ES 官方不推荐使用 G1,因为 Lucene 在 G1 下会出现数据丢失的 bug。
Do not, under any circumstances, run Lucene with the G1 garbage collector. Lucene’s test suite fails with the G1 garbage collector on a regular basis, including bugs that cause index corruption. There is no person on this planet that seems to understand such bugs (see https://bugs.openjdk.java.net/browse/JDK-8038348, open for over a year), so don’t count on the situation changing soon.
要尽一切可能避免系统 swap 内存。
不建议直接关闭 swap,应该调整 swappiness 来让系统降低 swap 的频率。swappiness 的取值范围为 0-100,0 表示仅在 OOM 时 swap,100 表示系统会尽一切可能 swap,默认值为 60,ES 建议设置为 1。
# 查询 swappiness
cat /proc/sys/vm/swappiness
# 设置
sudo vi /etc/sysctl.conf
vm.swappiness = 1
如果无法修改系统参数,可以修改 ES 的参数 mlockall,该参数会让 JVM 锁定进程的地址空间始终在内存内,避免被 swap:
bootstrap.memory_lock: true
# 查看是否启用 mlockall
GET _nodes?filter_path=**.mlockall创建新文档(indexing)的操作分为两步:refresh 和 flush。
Refresh:
每一个 shard 都有多个连续的 segment 组成,segment 是不可变的,所以每一次的 update 都意味着两步:
Flush:
translog 每 5s 就被提交到磁盘一次,可以通过 index.translog.flush_threshold_size 调整 translog 刷新的大小阈值。
涉及的指标:
indices.indexing.index_totalindices.indexing.index_time_in_millisindices.indexing.index_currentindices.refresh.totalindices.refresh.total_time_in_millisindices.flush.totalindices.flush.total_time_in_millis通过监控 indexing latency,可以了解 ES 是否逼近写入极限。
适当的制定 shards 数,让 index 分散于各个 node 之上,提高并发性能。
关闭 merge throttling,如果 ES 发觉有 merging 操作失败,就会自动会 index 进行限流,可以通过将 indices.store.throttle.type 设置为 none 来关闭这一功能。
提高 index buffer,indices.memory.index_buffer_size 默认为 10%。
在初始化 index 并需要执行大量 index 的时候,可以先不要设置 replicas,等大批量写入完成后,再设置 replica,可以显著提高性能。
默认每秒执行一次 refresh,降低 refresh 频率可以提高写入性能。
ES 2.0 以后,会在每一次 request 后 flush translog,设置 index.translog.durability=async 可以将 flush 设置为异步,并通过 sync_interval 设置刷新间隔。
需要注意的是,primary shards 数仅在创建 index 时可以指定,之后无法修改。只能通过创建新 index 再 reindex 的方式来实现扩展。
GET /_settings
创建 index 时,可以指定文件系统,可用选项有:
fs:系统默认,系统兼容性好;simplefs:并发性能差;niofs:并发效率高,不支持 windows;mmapfs:使用 mmap推荐使用 niofs。